こんにちは、データ基盤チームの大洞です。
2021年4月にANDPADにジョインしてから、データ基盤やデータ分析にかかわってきました。
今回は、データ分析を効率的にするために、DataWareHouse、DataMartを整備した話を紹介したいと思います。
データ基盤の全体像
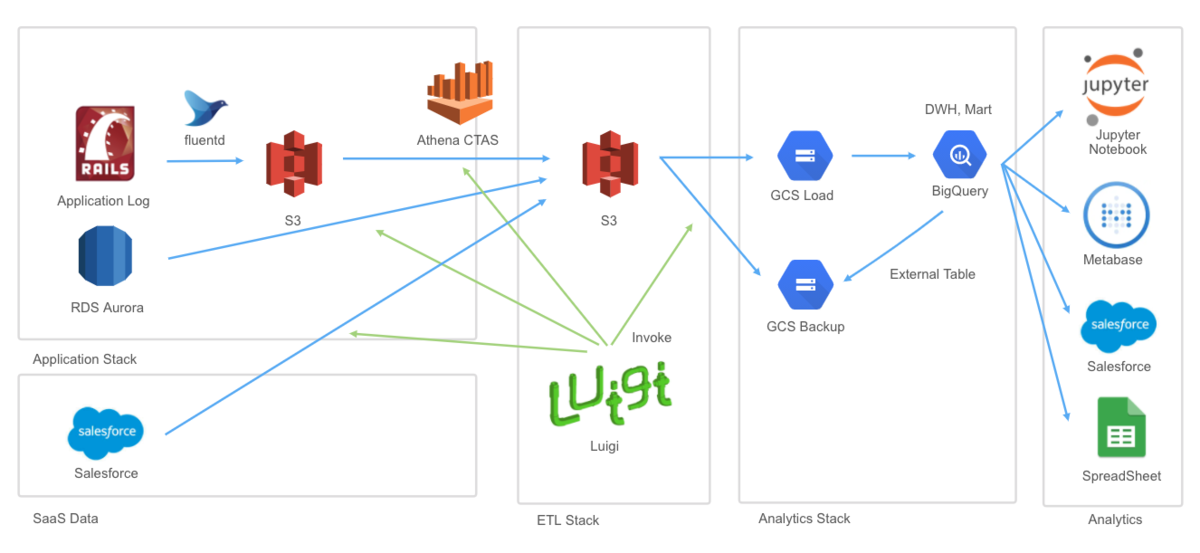
まずは、簡単にデータ基盤の全体像を紹介します。
左から順に説明していきます。
① SaaS Data
実際に稼働しているANDPADのDBやSalesforceなどの業務で利用しているサービスです。ここからデータを出力し、S3に保存します。
②ETL Stack
分析はBigQueryで行っているので、ここからGCSに移動させます。
③Analytics Stack
GCSに移動されたファイルをBigqueryにロードします。
④Anatytics
用途に応じて、Jupyter、Metabase、スプレッドシートなどで分析していきます。
整備前の課題
整備前は、単純にSaaSのRDSなどのテーブルをBigQueryに移しているだけでした。この状態だと以下のような課題が発生していました。
1. 分析の度に長いSQLを書くことになる
分析時に一つのテーブルだけを利用することはほぼなく、複数のテーブルを結合することがほとんどです。そのため、データを分析するたびに大量のinner joinを書かなければいけない状況になっていました。コードも長くなり、別の人が見たときに理解するのも大変な状況でした。
2. SQLを再利用できない
顧客であれば顧客関連のテーブル、物件であれば物件関連のテーブルを結合してから使う、というように途中で作成されるデータは大体同じになることが多いです。そのため、分析の度に似たようなコードが作成されてしまい、時間がかかったり、同じような集計で数値が微妙に変わってくるといった問題が起きてしまっていました。
3. 他の人の知見が生かせない
このテーブルを扱うときは実は state = 1で絞らなければいけない、この列は途中で追加されたので date で絞って分析しなければいけない、など初めて分析すると躓くポイントは、どの企業にもあると思います。こういった知見やノウハウはANDPADにもあるのですが、新しい人が入るたびに同じ罠にはまってしまうという状況でした。
以上のような課題もあり、直接移したテーブルを使うのではなく、DataWareHouse、DataMartを整備することになりました。
構成のポイント
設計の重要なポイントは以下の3つです。
1. DataLake、DataWareHouse、DataMart、APP の構成
2. スタースキーマによるDataWareHouse、DataMartの設計
3. Dataformの利用
1. DataLake、DataWareHouse、DataMart、APP の構成
大まかに分けて4段階の構成になっています。
| 構成 | 詳細 |
| DataLake | RDSなどのテーブルをそのまま移したもの |
| DataWareHouse | DataLakeのテーブルを加工し、分析に使いやすくしたもの |
| DataMart | データを集計したもの |
| APP | BIなどから直接参照するもの |
DataLakeは、csvなどの形でストレージに作成するのが一般的だと思いますが、それとは別にBigqueryにも作成しています。また、APPには最終的なアウトプット用のテーブルを用意しています。
2. スタースキーマによるDataWareHouse、DataMartの設計
DataWareHouseとDataMartで使いやすい形でデータを保存するため、スタースキーマと呼ばれる構造で設計を行いました。これは2種類のテーブルを使った設計になります。
| テーブル名 | 詳細 | 例 |
| ディメンションテーブル | あるカテゴリのデータを格納したもの | 場所、商品、顧客、時間 |
| ファクトテーブル | 分析対象の数値データを格納したもの | 気温、在庫、売り上げ |
ファクトテーブルには数値の値と関連したディメンションのキーを持ちます。ディメンションテーブルにはそのキーに関連する情報を格納しています。ファクトテーブル一つに対して、様々なカテゴリのディメンションテーブルをもつので、その形がスタースキーマと呼ばれています。この構造のメリットはいろいろありますが、私が良いなと思ったのは以下の2点です。
- クエリのパフォーマンスがよいこと
- データの構造がわかりやすいこと
詳細は、wikiなどを参照してください。
ja.wikipedia.org
3.Dataformの活用
Dataformと呼ばれるツールを導入しました。いろいろ機能はあるのですが、実現したかった点は以下の点です。
- 加工のクエリを管理できる。
- クエリの依存関係を表示する。
- パイプラインを定期実行する。
- データの質を担保するためのテストを実施する。
ちなみに、似たようなツールとしてdbtと呼ばれるツールもあり、両者を比較して導入しました。
結果
以上のような設計によって、データ分析において、質の面でも速度の面でもかなりの改善がみられました。具体的な改善点をあげると以下の通りです。
DataLake、DataWareHouse、DataMart、APP の構成
- 分析の度にやっていた似たような処理を書かず、DataWareHouse、DataLakeにある加工済みのデータを利用すればよくなりました。
- 他の人のノウハウがDataWareHouse、DataMartに反映されるようになり、分析速度が上がりました。
- 今までアウトプットを出すためのクエリはMetabaseなどにバラバラに存在したが、APPにあるため管理しやすくなりました。
スタースキーマの導入
- DataWareHouse、DataMartにおいて拡張性の高いデータ構造をつくれるようになりました。
- ファクトテーブルとディメンションテーブルが分かれていることで、ほしいディメンションのデータのみを取得できるようになりました。
Dataformの導入
- データのテストが実施されるようになったことで、データの質が向上しました。この列は本当にuniqueなのか?、本当にnullがないのか?といったことを気にしないで作業ができるようになりました。また、重要な場所にテストを仕込んでおくことでテーブルの構造の変化や内容の変化に気が付きやすくなりました。
- クエリがgitでコード管理できるようになりました。
- 依存関係を可視化したことで、DataWareHouseやDataMartの変更や削除がやりやすくなりました。
- データの加工をすべて管理し、BIツールなどのアウトプットを管理しやすくなりました。データに変更があるとエラーが通知されるようになったので、ダッシュボードを作ったけど、テーブルの変更が反映されずいつのまにか壊れている・・・といった事態がなくなりました。
まとめ
データの収集と可視化はデータを用いた経営をしていくための第一歩になります。しかし、この半年間を通じて単に集計するというだけでもそう簡単ではなく、改善の余地が多いことを実感しました。これからもデータ基盤を改善しさらに使いやすい基盤を作っていきたいと思います!
最後に
アンドパッドではデータ基盤はもちろん、一緒にサービス改善、プロダクト開発をすすめる仲間を募集しております!
詳しくは下記サイトをご覧ください。
engineer.andpad.co.jp