この記事はANDPAD Advent Calendar 2023の11日目の記事です。
はじめに
こんにちは、SWEの西です。普段はANDPADチャットを開発するチャットチームのメンバーとして働いています。今回はANDPADチャットのデータベースとして使われているFirestoreについてお話します。
FirestoreはGCPが提供するフルマネージドのNoSQL製品です。フルマネージドNoSQLのもう一つの代表例にAWSのDynamoDBがありますね。Firestoreにしかない特徴の一つとして、データの更新をリアルタイムでクライアントに反映できるというものがあります。この特徴はチャット機能と非常に相性が良いため、ANDPADチャットではFirestoreを採用しています。そんなFirestoreですが弱みもあります。その一つがバックアップ機能です。DynamoDBとFirestoreはどちらもポイントインタイムリカバリ(PITR)に対応していますが、データの保持期間を比べると前者は35日間、後者は7日間という違いがあります。バックアップに関してリアルタイム性と保持期間の両方が求められる場合は、懸念事項の一つになり得るでしょう。
この記事では、Firestoreのこのような弱点を、FirebaseエクステンションのStream Firestore to BigQueryを使って克服した事例を紹介します。このエクステンションは、FirestoreのデータをリアルタイムでBigQueryに同期してくれるものです。本来はデータの分析や集計のために使うことが想定されているようですが、使い方を工夫することで、長期間のPITRを実現する手段としても使えます。
それでは具体的な方法を見ていきましょう。
エクステンションのインストール
まずはエクステンションをインストールします*1。インストールはCLIまたはFirebaseコンソールのどちらからでも行えます。CLIを使う場合はこちらのドキュメントのHow to install を参照してください。Firebaseコンソールを使う場合はFirebase Extensions HubでStream Firestore to BigQueryを検索し、画面の案内に従ってインストールしてください。インストール時には、BigQueryに同期するFirestoreのコレクションを一つ指定します*2。インストールが完了すると、BigQueryにx_raw_changelogというテーブルとx_raw_latestというビューが作成されます(xにはコレクション名が入ります)。これらのテーブルとビューの詳細については後述します。
既存データのインポート
このエクステンションは、新規に書き込まれたデータについてはBigQueryに同期してくれますが、既存のデータについては別途インポートを行う必要があります。必要に応じてこちらの手順に従ってインポートを行ってください。
PITRへの応用
さて、ここからが本題です。これまでの作業で、FirestoreとBigQueryが同期した状態になっています。ここからはBigQueryに作られたテーブル/ビューを使ってPITRを行う方法を解説します。テーブル/ビューの構造を知っておくと理解の助けになるため、まずはそちらを見てみましょう。
BigQueryのテーブル/ビューの構造
エクステンションをインストールすると以下のテーブルとビューが作られます(xの部分にはインストール時に指定したコレクション名が入ります)。
- テーブル
- x_raw_changelog
- ビュー
- x_raw_latest
それぞれどのようなものか見てみましょう。
x_raw_changelogテーブル
このテーブルにはFirestoreの書き込み履歴が保存されます。カラムは以下のようになっています*3。
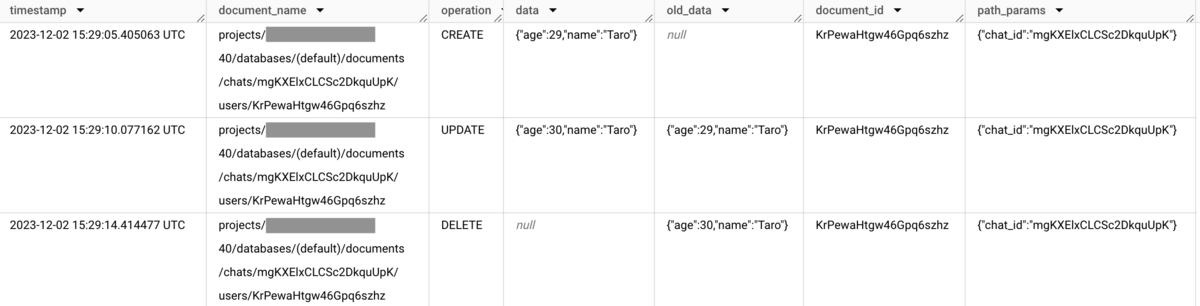
- timestamp
- Firestoreの書き込みが行われた日時(UTC)です。
- document_name
- 書き込みが行われたドキュメントのパスです。
- operation
- 書き込みの種類です。以下のいずれかの値をとります。
- IMPORT
- 既存データのインポート
- CREATE
- ドキュメントの作成
- UPDATE
- ドキュメントの更新
- DELETE
- ドキュメントの削除
- IMPORT
- 書き込みの種類です。以下のいずれかの値をとります。
- data
- 書き込みが行われた後のドキュメントを表すJSON文字列です。ドキュメントの全てのフィールドが含まれます。operationがDELETEの場合はnullになります。
- old_data
- 書き込みが行われる前のドキュメントを表すJSON文字列です。ドキュメントの全てのフィールドが含まれます。operationがCREATEの場合はnullになります。
- document_id
- 書き込みが行われたドキュメントのIDです。
- path_params
- ドキュメントがサブコレクションに属する場合は、親ドキュメントのIDがJSON形式で保存されます。
ここで意識したい点が二つあります。一つ目は、テーブルのレコードがリソースではなくイベントを表しているということです。すなわち、一つのドキュメントが一つのレコードとして保存されるわけではなく、ドキュメントが変更されるたびにその変更内容が新たなレコードとして保存されます。二つ目はdataというカラムの存在です。このカラムには、変更後のドキュメントの全てのフィールドの値が記録されます。たとえ一部のフィールドしか変更されなかったとしてもです。画像の例で言うと、UPDATE operationによってTaroのageが29から30に変更されていますが、dataカラムにはageだけでなくnameも含まれていますね。これらの点を踏まえてx_raw_latestビューを見てみましょう。
x_raw_latestビュー
このビューはx_raw_changelogテーブルから作られたもので、Firestoreのコレクションの最新の状態を表します。x_raw_changelogテーブルからどうやってコレクションの最新の状態を再現しているのでしょうか。ビューの定義*4を見てみましょう(解説のために添字を付しています)。
WITH latest AS ( SELECT max(timestamp) as latest_timestamp, -- (2-A) document_name FROM `my-project.firestore_export.x_raw_changelog` GROUP BY document_name -- (1) ) SELECT t.document_name, document_id, timestamp as timestamp, ANY_VALUE(event_id) as event_id, operation as operation, ANY_VALUE(data) as data, ANY_VALUE(old_data) as old_data, path_params as path_params FROM `my-project.firestore_export.x_raw_changelog` AS t JOIN latest ON ( -- (2-B) t.document_name = latest.document_name AND ( IFNULL(t.timestamp, timestamp("1970-01-01 00:00:00+00")) ) = ( IFNULL( latest.latest_timestamp, timestamp("1970-01-01 00:00:00+00") ) ) ) WHERE operation != "DELETE" -- (3) GROUP BY document_name, document_id, timestamp, operation, path_params
クエリを見てみると、まずドキュメント毎にグルーピングして(1)、最新の履歴データを抽出していますね(2-A、2-B)。そして最後にoperationがDELETEのものを除外しています(3)。つまり、削除されていないドキュメントの最新の書き込み履歴を取得しているわけです。dataカラムにはドキュメントの全フィールドの値が記録されているのでしたから、結果としてコレクションの最新の状態を表すビューができあがります。
任意の日時のデータを復元する方法
さて、察しの良い方ならすでにお気づきかもしれませんが、上のx_raw_latestビューのクエリを少し変えてやるだけで、任意の日時のデータを復元できます。以下は2023年1月1日 0時0分0秒 (UTC)時点のデータを復元する場合の例です。
WITH latest AS ( SELECT max(timestamp) as latest_timestamp, document_name FROM `my-project.firestore_export.x_raw_changelog` WHERE -- 追加 timestamp <= "2023-1-1 0:00:00" GROUP BY document_name ) -- 以下略
WITH latest AS(...)の中に WHERE timestamp <= "2023-1-1 0:00:00"という条件を追加しました。timestampはFirestoreの書き込み日時を表しているのでした。したがってこのクエリは、「2023年1月1日0時0分0秒以前の書き込み履歴の中から、各ドキュメントの最新の履歴を取り出す」という意味になります。つまり、指定した日時のスナップショットを取得できるわけです。あとはこのビューのデータをFirestoreに書き戻してやれば復元は完了です*5。ちなみに、document_name、path_params、dataなどのカラムでフィルタすることで、一部のドキュメントだけ復元することもできます。
-- chats/{chat_id}/users/{user_id}というドキュメント構造におけるusersコレクショングループを想定 -- 特定のuserだけ復元する場合 WHERE timestamp <= "2023-1-1 0:00:00" AND document_name = "projects/my-project/databases/(default)/documents/chats/FOO/users/BAR" -- 親ドキュメントのIDがFOOのuserだけ復元する場合 WHERE timestamp <= "2023-1-1 0:00:00" AND document_name LIKE "projects/my-project/databases/(default)/documents/chats/FOO/users/%" -- または WHERE timestamp <= "2023-1-1 0:00:00" AND JSON_EXTRACT_SCALAR(path_params, "$.chat_id") = "FOO" -- ageフィールドの値が30以下のuserだけ復元する場合 WHERE timestamp <= "2023-1-1 0:00:00" AND CAST(JSON_EXTRACT(data, "$.age") AS NUMERIC) <= 30
保持期間
保持期間については運用によりますが、x_raw_changelogテーブルのレコードを一切削除しない場合は実質的に無期限になります。最新でないレコードのうち一定日数が経過したものを削除するといった運用をする場合は、その日数が保持期間となります。
おわりに
この記事では、Firebaseエクステンションを使ってFirestoreをBigQueryに同期することで、長期間のPITRを実現する方法を紹介しました。「Firestoreの導入を検討しているけれどPITRの保持期間がネックになっている」といった場合は是非参考にしてみてください。
アンドパッドでは、「幸せを築く人を、幸せに。」というミッションの実現のため、一緒に働く仲間を大募集しています。ご興味を持たれた方は、下記のサイトをぜひご覧ください。 engineer.andpad.co.jp
参考資料
- https://extensions.dev/extensions/firebase/firestore-bigquery-export
- https://github.com/firebase/extensions/blob/master/firestore-bigquery-export/guides/IMPORT_EXISTING_DOCUMENTS.md
- https://github.com/firebase/extensions/blob/01d9102bed2f33b0784a6a0f2b4646e3034c904a/firestore-bigquery-export/firestore-bigquery-change-tracker/src/bigquery/schema.ts#L139
*1:エクステンションの利用には料金がかかります。詳しくはこちらを参照してください。
*2:複数のコレクションを同期したい場合は複数回インストールする必要があります。コレクショングループも指定可能です。
*3:一部を抜粋しています。実際のスキーマ定義はこちらを参照してください。
*4:x_raw_latestビューのクエリは、インストール時の設定項目"Use new query syntax for snapshots"で"yes"を選択したかどうかで内容が変わります。ここでは"yes"を選択した場合の例を記載しています。
*5:実際の事例では書き戻し用のプログラムを別途実装しています。並行処理が得意なGoで実装しました。