1. はじめに
こんにちは、SWEのあかりです。
今回は、SREの角井さん(@cass7ius)と一緒に、Kubernetes(以降、K8sと表記)のPodを事前にスケールアウトする仕組みをK8sのCronJobで構築したので、その実装背景・技術選定・実装方法について実例を紹介します。
この記事を読んで得られるものは以下の3点です。
- Podを事前にスケールアウトさせて、ジョブの遅延を低減した実例
- 技術選定時に行った定性分析の実例
- Podからkubectlコマンドを実行する実装例
2. 前提の説明
掲題の実装対象は施工管理サービスであり、これは社内で最も古くから稼働しているモノリシックなRailsアプリケーションです。施工管理サービスのおおよそのインフラ・技術構成は下図の通りになっています。
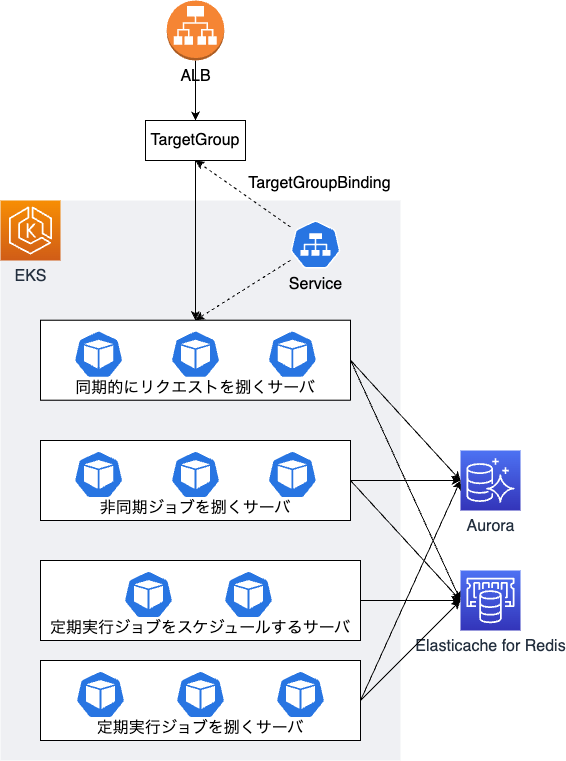
上図の通り、施工管理サービスはEKSクラスター上で稼働しており、おおよそ以下4つのサーバ群から構成されています。
- 同期的にリクエストを捌くサーバ
- 非同期ジョブを捌くサーバ
- 定期実行ジョブをスケジュールするサーバ
- 定期実行ジョブを捌くサーバ
そして、これらのサーバのうち定期実行ジョブをスケジュールするサーバ以外は全てオートスケールするように設定されており、同期的にリクエストを捌くサーバはHorizontal Pod Autoscalerを利用し、CPUとメモリの使用状況を見てオートスケールしています。一方で、非同期ジョブを捌くサーバと定期実行ジョブを捌くサーバはWatermark Pod Autoscaler(以降、wpaと記載)を利用しており、待機中ジョブの数に応じてオートスケールするように設定されています。ちなみに、非同期ジョブを捌くサーバと定期実行ジョブを捌くサーバとを分離している理由はデプロイ戦略が異なるからであり、非同期ジョブを捌くサーバはBlue/Greenデプロイしている一方で、定期実行ジョブを捌くサーバは単にRollingUpdateしています1。また、この施工管理サービスは、非同期処理にはSidekiqを採用しており、定期実行ジョブのスケジュール管理にはsidekiq-schedulerを採用しています。
3. 実装背景
施工管理サービスの定期実行ジョブの一つに、施工管理サービスのユーザーへ各種通知(メール通知やプッシュ通知など)を送信するためのジョブがあります。このジョブが毎朝8時に大量実行されるのですが、全てのジョブの完了に時間がかかっており、通知の遅延が発生する問題がありました。というのも、朝8時を境にして定期実行ジョブの数が急激に増加するため、下図のBeforeのように定期実行ジョブを捌くサーバのスケールアウトが間に合っていなかったからです。よって、下図のAfterに示すように、朝8時の直前に定期実行ジョブを捌くサーバを事前にスケールアウトさせることで、可能な限り処理の遅延を低減させることにしました2。
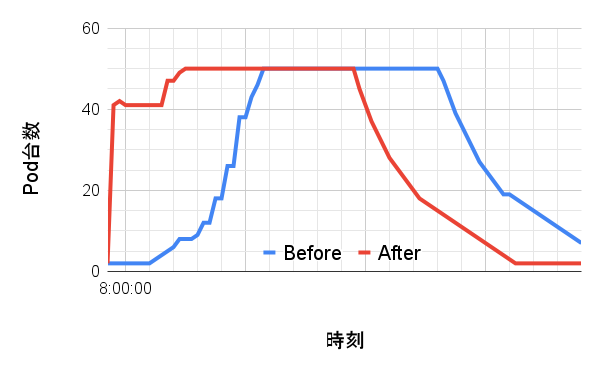
(Before: 事前スケールアウトなし、After: 事前スケールアウトあり)
4. 技術選定
4-1. Podをスケールアウトさせるkubectlコマンド
定期実行ジョブを捌くサーバを事前にスケールアウトさせる方法としては、以下の2通りが考えられました。
- 朝8時直前にkubectl scaleコマンドを実行し、ReplicaSetの数を一時的に増加させる方法
- 朝8時直前にkubectl patchコマンドを実行してwpaの最小Pod起動台数を一時的に増加し、その後にwpaの最小Pod起動台数を元に戻す方法
今回は、1の方法を採用しました。というのも、1の方法であればkubectlコマンドの実行が一回で済み、かつ、Gitリポジトリで管理しているK8sのマニフェストとK8s内部で管理しているマニフェストとに差が生じないからです。もちろん、kubectl scaleコマンド実行後にすぐにジョブが積まれない場合、定期実行ジョブを捌くサーバがどんどんスケールインしてしまう懸念がありますが、今回の要件の場合では問題ないだろうと判断しました。
4-2. kubectlコマンドの実行場所
次に、kubectlコマンドを定期実行する場所について検討し、次の3通りを候補として考えました。
- K8sのCronJob
- EventBridge + Lambda
- EventBridge + CodeBuild
そして、上記の技術に対して評価項目を選定し、下表のように定性分析を行いました。その結果、「実装の容易さ」と「維持・管理の容易さ」の観点で有利であることを重視し、K8sのCronJobを採用することにしました。
| K8sのCronJob | EventBridge + Lambda | EventBridge + CodeBuild | |
|---|---|---|---|
| 実装の容易さ | やや易 1. 既存のHelmチャートにCronJobとServiceAccountを追加しつつ、 kubectl scaleコマンドの実行権限を付与する(=RBAC認可の編集)。2. 参考にできる実装が社内に存在する。 |
やや難 1. Terraformによる実装。 2. 参考にできる実装が社内に存在しない。 3. Lambda関数に割り当てるIAMロールに kubectl scaleコマンドの実行権限を付与する(=aws-authとRBAC認可の編集)。 |
普通 1. Terraformによる実装。 2. 参考にできる実装が社内に存在する。 3. CodeBuildに割り当てるIAMロールに kubectl scaleコマンドの実行権限を付与する(=aws-authとRBAC認可の編集)。 |
| 維持・管理の容易さ | やや易 定期実行ジョブを捌くサーバの挙動が定期実行ジョブ用のチャート内の定義でほぼ完結する。 |
やや難 必要なコードが多く、その定義場所も散らばってしまうので、認知負荷が高い。 (a) LambdaとEventBridgeのTerraformコード (b) Lambda関数に割り当てるIAMロールに対して kubectl scaleコマンドの実行権限を付与するための定義(c) Lambda関数で実行するスクリプト |
やや難 必要なコードが多く、その定義場所も散らばってしまうので、認知負荷が高い。 (a) CodeBuildとEventBridgeのTerraformコード (b) CodeBuildプロジェクトに割り当てるIAMロールに対して kubectl scaleコマンドの実行権限を付与するための定義(c) buildspec |
| 起動の速さ | 普通 1. リソースがスケジュールされてから、Podを起動して kubectl scaleコマンドを実行するまでにやや遅延がある。2. ただし、リソースのスケジュールを阻害する要因はあまりなく、顕著に遅れることはないと考えられる。 3. 何らかの理由で kubectl scaleコマンドの実行に失敗した場合は、kubectlコマンドの実行が遅れる可能性がある。 |
速(実装次第) 1. コンテナの起動時に kubectl scaleコマンドを実行する実装にすることで、kubectlコマンドの実行を速くできる。2. コールドスタートの場合でも、遅延は数秒程度に抑えることができる。 |
やや遅い(実装次第) 1. コンテナの起動時に kubectl scaleコマンドを実行する実装にすることで、kubectlコマンドの実行を速くできる。2. ただし、プロビジョニングにかかる時間が若干遅く、かつ、ばらつきが大きい。 |
| ログの収集方法 | 1. Datadog Logs (標準出力をDatadog Logsに送信させる。) 2. 念の為、失敗したPodを残すようにする。 |
CloudWatch Logs | CloudWatch Logs |
| 追加で発生するインフラコスト | ほぼ無 既存のEKSクラスターにPodが1台追加されるのみ(もちろん、その他にも付属物はある)。 |
中 K8sのCronJobよりは高くなる。 |
高 Lambdaより高い。 |
つまり、定期実行ジョブを捌くサーバを事前にスケールアウトさせるための仕組みは下図のようになります。
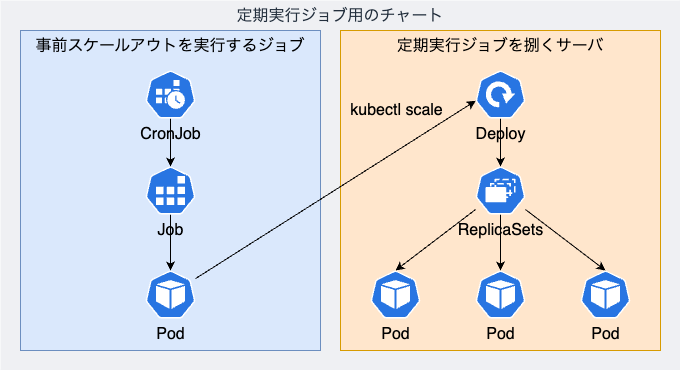
この構成の唯一優位でない点として、kubectl scaleコマンドの実行に10秒程度の遅延4が発生することが挙げられました。ですが、今回はこの観点はあまり重要度が高くないと判断しました。というのも、そもそもkubectl scaleコマンドの最適な実行タイミングを秒単位で把握することは難しく、たとえそれが可能だとしても、秒単位でのCron設定はできない5からです。
5. 実装詳細
実装したことは大きく次の3つです。
kubectl scaleコマンドを実行するCronJob(以降、事前スケールアウトを実行するジョブと記載)を定義し、ServiceAccountを紐付ける。- 「定期実行ジョブを捌くサーバに対して
kubectl scaleコマンドを実行する権限」を「事前スケールアウトを実行するジョブのServiceAccount」に付与する。 - 事前スケールアウトを実行するジョブのログをDatadogへ送信し、このジョブが何らかの理由で失敗した場合には、Datadogのログモニターを利用して、Slackにアラート通知を送信する。
詳細説明は省きますが、1のマニフェストを以下に示します。実際はHelmを利用しているため、わかりやすくするために修正したものを表示しています。
apiVersion: batch/v1 kind: CronJob metadata: name: 「事前スケールアウトを実行するジョブ」名 labels: # 省略 spec: schedule: "59 22 * * *" successfulJobsHistoryLimit: 0 failedJobsHistoryLimit: 1 concurrencyPolicy: Forbid jobTemplate: spec: template: metadata: annotations: # 省略 labels: # 省略 spec: serviceAccountName: 「事前スケールアウトを実行するジョブ」のServiceAccount名 containers: - name: コンテナ名 image: bitnami/kubectl:1.24 command: - kubectl - scale - deployments.apps/「定期実行ジョブを捌くサーバ」名 - --namespace=「定期実行ジョブを捌くサーバ」が存在するネームスペース名 - --replicas=50 restartPolicy: OnFailure
apiVersion: v1 kind: ServiceAccount metadata: name: 「事前スケールアウトを実行するジョブ」のServiceAccount名 # 省略
また、2のRBAC認可を定義したマニフェストを以下に示します。ここは意外に最も苦戦したところで、kubectl scaleコマンドを実行する最小権限の調査と特定に試行錯誤しました。以下にマニフェストを示しますが、もう少し権限を削ぎ落とす余地があると思っているので、この場合の適切な最小権限についてノウハウのある方は、ぜひブログにコメントを残していただけるとありがたいです。
kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: 「定期実行ジョブを捌くサーバ」に対してkubectl scaleコマンドを実行する権限 namespace: 「事前スケールアウトを実行するジョブ」が存在するネームスペース rules: - apiGroups: - apps resources: - deployments - deployments/scale resourceNames: - 「定期実行ジョブを捌くサーバ」名 verbs: - get - list - update - patch
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: 「事前スケールアウトを実行するジョブ」名 namespace: 「事前スケールアウトを実行するジョブ」が存在するネームスペース subjects: - kind: ServiceAccount name: 「事前スケールアウトを実行するジョブ」のServiceAccount名 roleRef: kind: Role name: 「定期実行ジョブを捌くサーバ」に対してkubectl scaleコマンドを実行する権限 apiGroup: rbac.authorization.k8s.io
6. まとめ
この記事では、Podのオートスケールが間に合わずにジョブの処理が遅延していた問題を、K8sのCronJobからkubectl scaleコマンドを実行してPodを事前にスケールアウトさせることで改善した実例を紹介しました。ここでは、技術選定時の思考プロセスと実装の詳細について記載しましたので、どなたかの参考になれば幸いです。
今回はPodの事前スケールアウトという技術的観点から問題を改善しましたが、本件は仕様変更の観点からも問題を改善できる余地があると考えています。つまり、メールが朝8時ちょうどに送信される必要が本当にあるのか、見直す余地がありそうということです。ですので、引き続き、仕様の再検討と議論を行いつつ、技術という枠に捉われずにバランスよく問題解決を図っていこうと思います。
7. 終わりに
アンドパッドでは、「幸せを築く人を、幸せに。」というミッションの実現のため、一緒に働く仲間を大募集しています。 チーム一丸となって良いプロダクトを作りたい!と思われる方はぜひぜひご応募ください! engineer.andpad.co.jp
-
このような構成を採用した背景に興味のある方は、こちらの記事をご参照ください。また、現在の施工管理サービスのインフラ構成に至っている歴史的経緯については、以下の記事に詳細を記載しています。
1. ANDPAD本体サービスをEKSに移行しました
2. 施工管理サービスの定期実行ジョブ処理基盤をEC2からコンテナへ移行しました
3. 施工管理サービスの非同期処理基盤をBlue/Greenデプロイ化しました[前編]
4. 施工管理サービスの非同期処理基盤をBlue/Greenデプロイ化しました[後編]
5. データパッチ環境と有事の際のログイン環境をサーバレス化・コンテナ化した取り組み↩ - プロダクトの仕様を見直すことができないかも同時に議論しています。というのも、ジョブの数に応じてサーバ台数を無限にスケールアウトすることもできないので、ジョブの数が増えすぎると必ず処理遅延が発生するからです。↩
- あくまでイメージ図です。説明をわかりやすくするために、生データを加工して描画しています。ただし、事前スケールアウトした直後のPod数の変化は実際の挙動です。Podの台数を50台にスケールアウトするコマンドを実行した直後から、オートスケール指標に従ってPodがスケールインしてしまうため、事前スケールアウト直後のPod台数がおよそ40になっています。↩
- コンテナの起動が速度のボトルネックになると考えました。というのも、一日に一度だけ実行されるジョブですので、ワーカーノード上にイメージのキャッシュがない場合がほとんどだと推測されたからです。↩
-
もちろん、
kubectl scaleコマンドの実行前にsleepコマンドを挿入することで、コマンドの実行タイミングを秒単位で制御することは可能です。ですが、コンテナの起動にかかる時間がバラバラであることを踏まえると、やはり秒単位でコマンドの実行を制御することは簡単ではないと考えました。↩