こんにちは!ANDPADでエンジニアをしている谷澤です。先日Amazon Web Service (以下AWS) 社より生成AI関連機能についてのプライベートなハンズオンを開催いただきました。 社外の方にも雰囲気をお伝えできればと思います。
はじめに
私が所属するデータ部は、アンドパッド社内に蓄積されたデータを活用して、継続的にビジネス価値を創出していくことを目指しています。 直近では黒板AI機能をリリースしています。
上記の他にも複数のプロジェクトが進行しており、将来皆様にお伝えできるのを楽しみにしています。
Amazon Bedrock のハンズオン
アンドパッドは主要なクラウドとしてAWSを採用しており、AWS社の担当者の方と定期的な話し合いの場を設けています。 最近は生成AI関連機能であるAmazon Bedrockのアップデートが進んでおり、担当者の方から、Amazon Bedrockを簡単に試せるハンズオンの開催を打診いただきました。他プラットフォームの生成AIですでにPoCを行っていたものの、Amazon Bedrock については全く知識がなく非常にありがたい申し出でした。 当日はAWS社よりSolution Architect、Account Manager、Technical Account Managerの合計3名の方が参加され、ハンズオンを開催いただきました。 ハンズオンはAmazon Bedrockを画面上およびプログラム上から操作し生成AIを活用したシステムを実装するという内容で、所要時間は半日でした。
ハンズオンのコンテンツ
ハンズオンは以下のように進みました。
- Amazon Bedrock 紹介
- Knowledge Bases for Amazon Bedrock をコンソール画面で体験
- RAGシステムをKnowledge Bases for Amazon Bedrock を利用して実装 & ゼロから実装
- 検索ワード改善によるRAGシステムの精度向上
- 日本語を元にSQLクエリを自動生成するデモ
1. Amazon Bedrock紹介
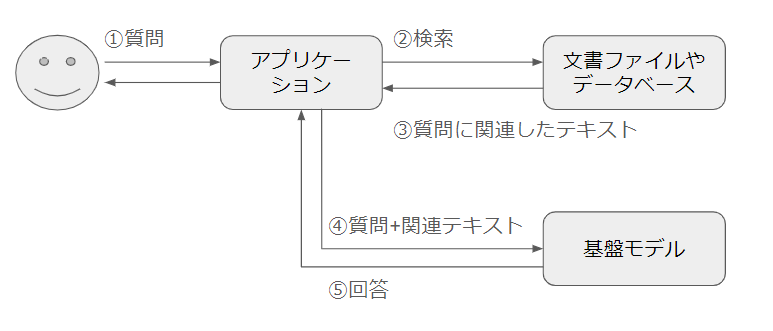
まずは座学でAmazon Bedrockについて紹介がありました。 Amazon Bedrockは基盤モデルの実行環境をサーバーレスで提供するサービスであり、生成AIを活用したアプリケーション開発を迅速に進めることができます。 Amazon Bedrockには検索拡張生成(RAG)*1を手軽に行うための Knowledge Base という機能があり、 S3バケットなどに保存したファイルを対象としてRAGを行うことができます。
2. Knowledge Base をコンソール画面で体験
コンソール画面上のチャットウインドウから Knowledge Base を使いRAGシステムを構築しました。 情報が書かれたpdfファイルをS3上にアップロードしボタンを数回クリックするだけでRAGシステムを構築出来る点が印象的でした。 裏側に自動で構築されるマネージドなインフラに対するコストは発生しますが、代わりにシステム構築/運用コストが削減できるというメリットがあり、エンジニアリソースが足りない場合に有益な機能だと感じました。
3. RAGシステムをKnowledge Base を利用して実装 vs ゼロから実装
前半は Knowledge Base を Python SDK 経由で利用しRAGシステムの実装を行いました。 具体的なソースコードは下記のとおりです。
import boto3 # RAG ハンズオンで作成した Knowledge base の情報。マネジメントコンソール上で確認可能。 knowledge_base_id = "XXXXXXXXXX" data_source_id = "YYYYYYYYYY" # 推論用生成AIモデルの情報 model_id = "anthropic.claude-v2:1" region = "us-west-2" # S3上のファイルを Knowledge base と同期 # 毎回実行する必要はなくファイルを更新した際のみ実行すればよい client = boto3.client('bedrock-agent') response = client.start_ingestion_job( knowledgeBaseId=knowledge_base_id, dataSourceId=data_source_id, ) # 質問文を入力しRAGを実行 question = 'Fire TV Stick 第3世代で視聴できる動画配信サービスを列挙してください。' client_runtime = boto3.client('bedrock-agent-runtime') response = client_runtime.retrieve_and_generate( input={ 'text': question }, retrieveAndGenerateConfiguration={ 'type': 'KNOWLEDGE_BASE', 'knowledgeBaseConfiguration': { 'knowledgeBaseId': knowledge_base_id, 'modelArn': f'arn:aws:bedrock:{region}::foundation-model/{model_id}' } } ) for i, citation in enumerate(response['citations']): # 回答本文を表示 print(citation['generatedResponsePart']['textResponsePart']['text']) for ref in citation["retrievedReferences"]: # reference となったファイルの S3 URI を表示 uri = ref["location"]["s3Location"]["uri"] print(f'({uri.replace("s3://", "https://s3.console.aws.amazon.com/s3/buckets/")})')
少ないコード量でRAGが実現できる点にメリットを感じました。
後半は Knowledge Base を用いずにゼロからRAGを実装しました。 詳細なソースコードは割愛しますが、ゼロから実装する場合、
- 「各種テキストを埋め込み表現ベクトル化する」
- 「埋め込み表現ベクトル同士の類似度を計算し、最も質問テキストに類似している資料テキストを抽出する」
- 「プロンプトに資料テキストを追加したうえで基盤モデルに問い合わせる」
というステップを実装する必要があり、Knowledge Base を用いる場合に比べ実装コストが大きくなります。 今回のハンズオンでは、 Knowledge Base を用いるパターン、ゼロから実装するパターンの両方を経験することで、Knowledge Base のありがたみを感じることができました。
4. 検索ワード改善によるRAGシステムの精度向上
RAGの精度向上のために、ベクトル検索の際に用いる検索ワードを基盤モデルに改善させる、という取り組みを体験しました。 RAGでは質問文をもとに類似したテキストを検索しますが、質問文が複雑になると適切な関連テキストを検索できなくなることがあります。 これを解決するために、質問テキストをそのまま検索に用いるのではなく、いくつかの単語(=キーワード)に変換してから検索を行います。
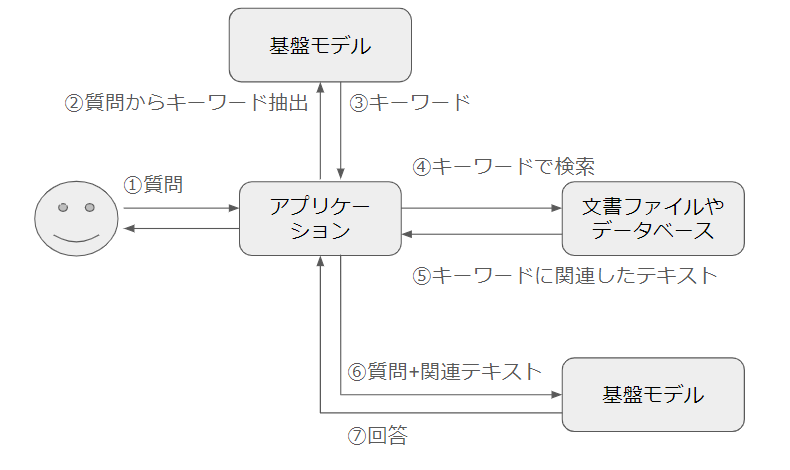
具体的な例は下記のとおりです
- 元の質問 - 私の祖母は植物の動画が大好きで、いつもスマホでYouTubeを見ています。そんな彼女に贈り物を贈りたいのですが、何を贈ると喜んでもらえるでしょうか? - キーワードを抽出した結果 - 祖母 YouTube 贈り物
今回のハンズオンでは十分に試す時間がなかったものの、RAGの検索ワードを変換するというアプローチ自体は精度が上がることが報告されているため、また別の機会に検証してみたいと思います。
5. 日本語を元にSQLを自動生成するデモ
データベースに保存されているデータについて、知りたいことを日本語で問いかけると基盤モデルがSQLを自動生成するデモも披露いただきました。 なお、これは通常のハンズオンのプログラムには無いもののようで、アンドパッドの状況に合わせてカスタマイズしてもらいました。 ありがたい限りです。
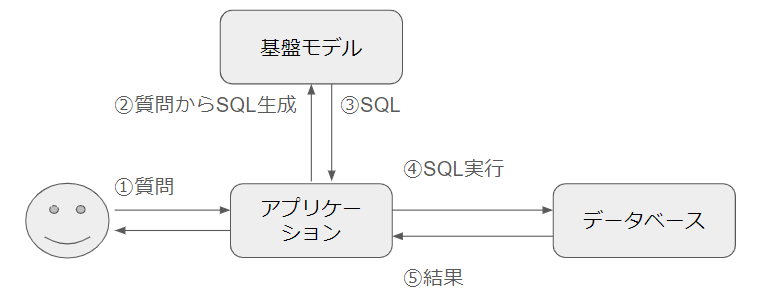
具体的な例は下記のとおりです
- 元の質問
- 従業員テーブルは次のクエリで作成されています。
- CREATE TABLE IF NOT EXISTS employees (
id INTEGER PRIMARY KEY,
name TEXT,
department TEXT,
salary INTEGER
)
- 部門ごとの平均給与は?
- 生成されたSQL
SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department;
生成されたクエリを実際にデータベースに投入し、意図通りに動作することも確認できました。 今回はテーブル1つに対する単純なクエリでしたが、メタデータなどをコメントで付与することで複雑なクエリにも対応可能とのことでした。 Amazon Bedrockとは別のサービスですが、Amazon Q in QuickSightや他社のクラウドではSQL自動生成機能や分析アシスタント機能の開発が進められており、この分野は今後も盛り上がっていきそうだと感じました。
最後に
参加前はAWSの生成AI関連機能について全く知識がありませんでしたが、ハンズオンで理解を深めることができました。 ハンズオンを担当頂いた3名の方には深く御礼申し上げます。最後の日本語を元にSQLを自動生成するデモまでカスタマイズして用意いただき、本当にありがとうございました。
アンドパッドでは一緒に働く仲間を大募集しています。
アンドパッドでは、「幸せを築く人を、幸せに。」というミッションの実現のため、一緒に働く仲間を大募集しています。 アンドパッドにおけるデータ活用の可能性は無限大で、AI・MLOps・データサイエンス・データアナリティクス・データエンジニアリング、どの切り口においても取り組むべき事柄がたくさんあります。様々な技術的課題にチームで挑戦する中で成長を遂げることができます。まずはカジュアル面談からでもご応募いただければより詳しい情報をお伝えできますので、是非ご応募いただければと思います。
*1:基盤モデルに質問する際に関連度の高い文章を添付することで回答の精度を上げる仕組み