1. はじめに
こんにちは、SWEのあかりです。
今回のテーマは、Go Conference mini 2023 Winter IN KYOTOのLT枠に応募したものの、残念ながら不採択になってしまったものです。話せるネタとしてはまとまっていたので、テックブログとしてここに捧げます😇
ちなみに、面白そうなセッションがたくさんあるので、現地参加はさせていただく予定です!
2. 記事の概要
この記事では、Go言語の標準パッケージdatabase/sqlの拡張であるsqlxを利用しているプロダクトにおいて、データベースの書き込み先/読み込み先エンドポイントを透過的に使い分ける実装1(以降、Read/Write分離と記載)について紹介します。
この記事を読んで得られることは以下の2点です。
- データベースの負荷分散手法の一つであるRead/Write分離の概要
- sqlxを利用しているプロダクトで透過的にRead/Write分離を実装する方法
3. 前提の説明
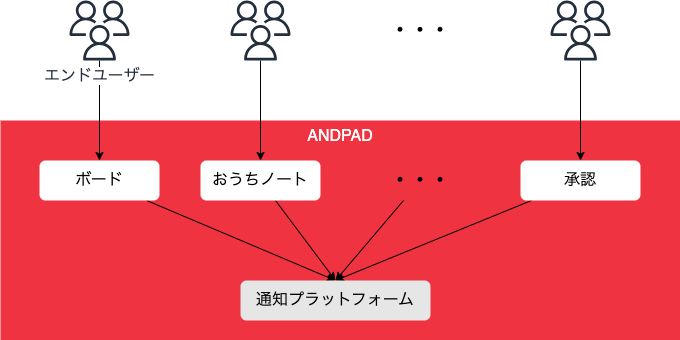
今回、データベースのRead/Write分離を実装したアプリケーションは社内の通知プラットフォームです。下図に示す通り、このサービスはANDPADを構成する複数プロダクトに対して、共通の通知機能を提供するマイクロサービスになります。
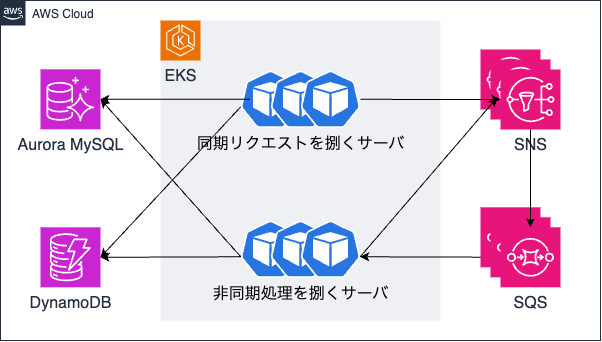
通知プラットフォームのおおよそのインフラ構成を下図に示します。アプリケーションはEKSクラスター上で稼働しており、データベースにはAmazon Aurora MySQLを利用しています。
アプリケーションの構成はクリーンアーキテクチャを意識した設計となっており、ディレクトリ構成はおおよそ以下のようになっています2。
. ├── cmd │ ├── api │ | └── main.go │ └── subscriber │ └── main.go └── internal ├── domain │ └── device.go ├── handler │ └── device.go ├── infrastructure │ ├── database │ │ ├── db_accessor.go │ │ └── db_accessor_test.go │ └── repository │ ├── device.go │ └── device_test.go └── usecase └── device.go
それぞれのパッケージの役割と処理の流れは以下の通りです。
handlerパッケージ:
- 主な役割は外部からのリクエストを受け取ってレスポンスを返すことです。
- 入力値のバリデーションチェックを行い、問題がなければビジネスロジックの処理を
usecaseパッケージに委託します。
usecaseパッケージ:
- このパッケージはアプリケーションの核となるビジネスロジックを実装しています。
- ビジネスロジックの中で必要なデータの取得や保存が生じた場合は
repositoryパッケージに処理を依頼します。ただし、トランザクション自体はusecaseパッケージの中で張ります。
repositoryパッケージ:
- データストアとのやり取りを抽象化して担当します。
- 具体的なデータストアの実装、例えばデータベースへのアクセス方法などは、
databaseパッケージを利用しています。
databaseパッケージ:
- 実際にデータベースとのやり取りを行います。
4. データベースのRead/Write分離とは
データベースのRead/Write分離とは、データベースを負荷分散する手法の一つです。下図に示すように、データベースの読み取りと書き込みとでエンドポイントを使い分けることで、データベースの負荷を分散させます。
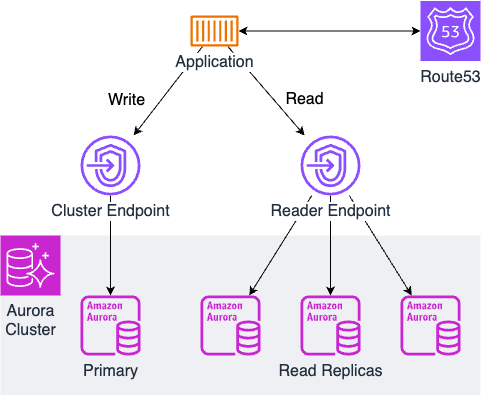
データベースのマネージドサービスとしてAmazon Auroraを利用している場合、実装は比較的容易です。というのも、Auroraクラスター作成時にクラスターエンドポイントとリーダーエンドポイントの両方が払い出されており、加えて、リーダーエンドポイントはラウンドロビン方式でリクエストが分散するようになっているからです。つまり、実装者がやるべきことは、Route53などのDNSサービスを利用してこれらのエンドポイントのエイリアスを作成し、アプリケーション側でこれらのエイリアスを読み取り時と書き込み時とで使い分けるようにするだけです。
5. コードの実例紹介
databaseパッケージの中身を以下に示します4。
package database import ( "context" "database/sql" "fmt" "github.com/jmoiron/sqlx" ) type ( DBAccessor struct { writer *sqlx.DB reader *sqlx.DB } abstractSqlxDB interface { BindNamed(query string, arg interface{}) (q string, args []interface{}, err error) ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error) QueryxContext(ctx context.Context, query string, args ...interface{}) (*sqlx.Rows, error) } ctxKeyTx struct{} ) func NewDBAccessor( writer *sqlx.DB, reader *sqlx.DB, ) *DBAccessor { return &DBAccessor{ writer: writer, reader: reader, } } func (dba *DBAccessor) Transaction(ctx context.Context, txFunc func(context.Context) error) (err error) { tx, err := dba.writer.Beginx() if err != nil { return fmt.Errorf("failed to begin transaction: %w", err) } defer func() { if r := recover(); r != nil { if err := tx.Rollback(); err != nil { // ログ出力 } err = fmt.Errorf("panicked on execution txFunc: %v", r) } }() txCtx := withTxDB(ctx, tx) if txErr := txFunc(txCtx); txErr != nil { if err := tx.Rollback(); err != nil { // ログ出力 } return txErr } if err := tx.Commit(); err != nil { return fmt.Errorf("failed to commit transaction: %w", err) } return nil } func (dba *DBAccessor) Exec( ctx context.Context, query string, arg interface{}, ) (sql.Result, error) { tx, err := getTxFromContext(ctx) if err != nil { return nil, fmt.Errorf("failed to getTxFromContext: %w", err) } var da abstractSqlxDB if tx != nil { da = tx } else { da = dba.writer } // prepare namedQuery, namedArgs, err := da.BindNamed(query, arg) if err != nil { return nil, fmt.Errorf("failed to BindNamed: %w", err) } namedQuery, namedArgs, err = sqlx.In(namedQuery, namedArgs...) if err != nil { return nil, fmt.Errorf("failed to sqlx.In: %w", err) } result, err := da.ExecContext(ctx, namedQuery, namedArgs...) if err != nil { return nil, fmt.Errorf("failed to run exec: %w", err) } return result, nil } func (dba *DBAccessor) Query( ctx context.Context, query string, arg interface{}, ) (*sqlx.Rows, error) { tx, err := getTxFromContext(ctx) if err != nil { return nil, fmt.Errorf("failed to getTxFromContext: %w", err) } var da abstractSqlxDB if tx != nil { da = tx } else { da = dba.reader } // prepare namedQuery, namedArgs, err := da.BindNamed(query, arg) if err != nil { return nil, fmt.Errorf("failed to BindNamed: %w", err) } namedQuery, namedArgs, err = sqlx.In(namedQuery, namedArgs...) if err != nil { return nil, fmt.Errorf("failed to sqlx.In: %w", err) } rows, err := da.QueryxContext(ctx, namedQuery, namedArgs...) if err != nil { return nil, fmt.Errorf("failed to run query: %w", err) } return rows, nil } func withTxDB(ctx context.Context, tx *sqlx.Tx) context.Context { return context.WithValue(ctx, &ctxKeyTx{}, tx) } func getTxFromContext(ctx context.Context) (*sqlx.Tx, error) { if v := ctx.Value(&ctxKeyTx{}); v != nil { tx, ok := v.(*sqlx.Tx) if !ok { return nil, fmt.Errorf("failed to convert to *sqlx.Tx: %v", v) } return tx, nil } return nil, nil }
このパッケージでは、DBAccessorという構造体を公開しており、そのフィールドに読み書きそれぞれのエンドポイントと接続している*sqlx.DBを格納しています。そして、TransactionとExecとQueryの3つのメソッドを公開しています。その名の通り、Transactionはトランザクション処理を行い、ExecとQueryはそれぞれデータベースに対する書き込みと読み取りを行います。これらのメソッドの呼び出し元についてですが、Transactionメソッドは基本的にusecaseパッケージから呼び出され、ExecとQueryメソッドはrepositoryパッケージから呼び出されます。というのも、3章でも説明した通り、ビジネスロジックはusecaseパッケージに記述し、個別のデータストアとのやり取りはrepositoryパッケージに記述しているからです。
続いて、読み書きのエンドポイントを透過的に切り替えるロジックを説明します。トランザクション処理を行わない場合は単純で、デフォルトでExecメソッドは書き込み用の*sqlx.DBを利用し、Queryメソッドは読み込み用の*sqlx.DBを利用しています。一方で、トランザクション処理を行う場合は、usecaseパッケージで呼ばれたTransactionメソッドの中でcontextに*sqlx.Txを埋め込み、repositoryパッケージで呼ばれたExecやQueryメソッド内でcontextから*sqlx.Txを取り出して利用するようになっています。つまり整理すると、基本的にはExecとQueryのメソッド単位で読み書きを切り替えており、その上で、トランザクション処理を行う場合のみcontextを介して渡した*sqlx.Txを利用してデータベースへの読み書きを行なっているのです。
文章だけではトランザクション処理を行う場合の実装イメージがつきにくいかもしれません。ですので、サンプルとしてusecaseパッケージからTransactionメソッドを呼び出すコード例を以下に記載しておきます。興味のある方は展開して確認してください。注意点としては、Transactionメソッドに渡される関数内では必ずその関数のcontextを利用してメソッドを呼び出すことです。こうすることで、Transactionメソッドに渡した関数内では*sqlx.Txを利用した処理が行われるようになります。
usecaseパッケージからTransactionメソッドを呼び出すサンプルコード
package usecase import ( "context" "fmt" ) type transactioner interface { Transaction(context.Context, func(context.Context) error) error } type unreadCountRepository interface { GetForUpdate() // 省略 Increment() // 省略 } type notifyUserDetailsUsecase struct { dba transactioner unreadCountRepository unreadCountRepository // 省略 } func (u *notifyUserDetailsUsecase) NotifyUserDetails( ctx context.Context, // 省略 ) error { // 省略 if txErr := u.dba.Transaction(ctx, func(txCtx context.Context) error { if _, err := u.unreadCountRepository.GetForUpdate( txCtx, // 省略 ); err != nil { return fmt.Errorf("failed to lock unread count: %w", err) } if err := u.unreadCountRepository.Increment( txCtx, // 省略 ); err != nil { return fmt.Errorf("failed to increment unread count: %w", err) } return nil }); txErr != nil { return fmt.Errorf("failed to dba.Transaction: %w", txErr) } return nil }
6. まとめ
この記事では、データベースのRead/Write分離について説明し、sqlxを利用したプロダクトでそれを透過的に切り替える実装例を紹介しました。現在データベースの負荷分散を検討している方や、これからデータベースのRead/Write分離を実装しようと検討中の方々にとって、何か設計のヒントになれば幸いです。
7. 最後に
アンドパッドでは、「幸せを築く人を、幸せに。」というミッションの実現のため、一緒に働く仲間を大募集しています。 チーム一丸となって良いプロダクトを作りたい!と思われる方はぜひぜひご応募ください! engineer.andpad.co.jp
- 「開発者が意識せずとも、自然にデータベースの読み込み先エンドポイントと書き込み先エンドポイントが切り替わるような実装」という意味です。↩
- 説明の都合上、多少加工しています。↩
-
以下の記事を参考にして描画しています。
オープンソースプラットフォームで ProxySQL を使用して、Amazon Aurora クラスターでの SQL の読み取りと書き込みを分割する方法↩ - 説明の都合上、実際のコードを修正して記載しています。↩