はじめまして、開発部の@taikishiinoです。 2020年3月にアンドパッドにジョインし、約一年が経ちました。
現在、チャットサービスの開発・運用をするチームに所属しており、その中で最近、RDSからFirestoreへのデータ移行を行いました。
本記事では、その際の課題やそれに対して実際に行ったことなどを中心にご紹介していきます。
データ移行の背景
僕たちのチャットサービスを開発するチームでは、現在、プロダクトのデータベースをRDSとFirebase RealtimeDatabaseのミックスからFirestoreに移行する大規模プロジェクトが行われています。
旧環境「RDSとFirebase RealtimeDatabase」の課題として、 チャットのアクセスを処理しているAPIサーバーのバックグラウンド処理は複数プロダクト共通で利用しており、チャット起因で負荷が高まってしまうということがありました。
Firestore移行プロジェクトによって、バックグラウンド処理を分離することで負荷軽減を実現したいと思っています。 また、個人的なモチベーションとしては、Firestoreにデータを寄せることによる、各機能のリアルタイム化とパフォーマンスアップにも期待しています。
そして、ユーザーへのリリースとしては、以下の仕組みによる安全なリリースを予定しています。
- ユーザーが投稿したデータをRDSとFirestore両方に同期する仕組み
- クライアント(Web・アプリ)の接続先を切り替えられる仕組み
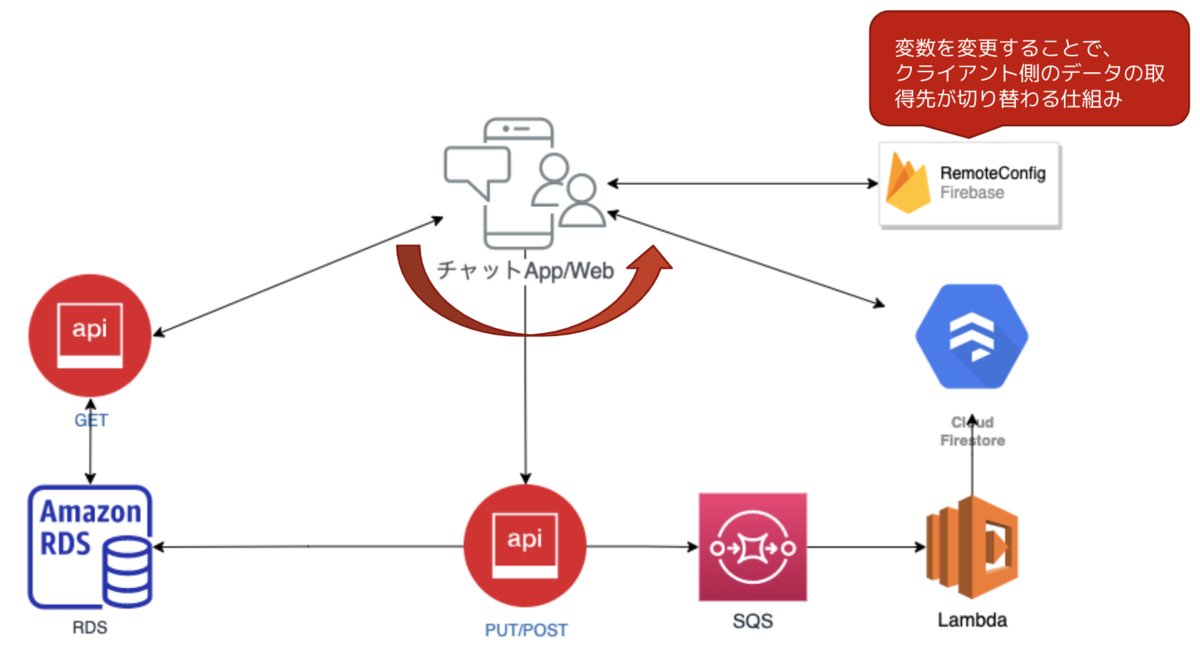
このリリースの前提条件として、運用初期からRDSに蓄積されているデータを全てFirestoreに移行する必要がありました。
まさにこの「RDS→Firestoreのデータ移行」の内容が、今回ご紹介する内容になります。では、いよいよここから本題に入ります。
データ移行の課題
主に以下の3つありました。
- 対象データが約5000万件ある
- 本番DBへの負荷がかかる
- 移行元のDBと移行先のFirestoreでデータ構造が異なる
対象データが約5000万件ある
プロダクトの特性上、更新頻度の多いデータが多く、運用初期から蓄積されたデータが約5000万件もありました。
本番DBへの一定の負荷がかかる
接続するDBへ一定の負荷がかかることが予想されるため、サービス停止前提でのデータ移行を想定していました。 サービス停止とはいっても、何時間もサービス止めておくわけにはいかないので、理想的には1,2時間ほどでデータ同期しきる処理パフォーマンスが求められることがわかっていました。
移行元のDBと移行先のFirestoreでデータ構造が異なる
データ構造を変換した上でFirestoreに同期するので、データ同期後に想定通りにデータ同期できているかをデータ検証する仕組みが必要と考えていました。
最終的なデータ移行の構成
上記の課題を踏まえて、以下の2つのツールを開発しました。
- 同期ツール:データを同期する仕組み
- 検証ツール:同期したデータの整合性をチェックする仕組み
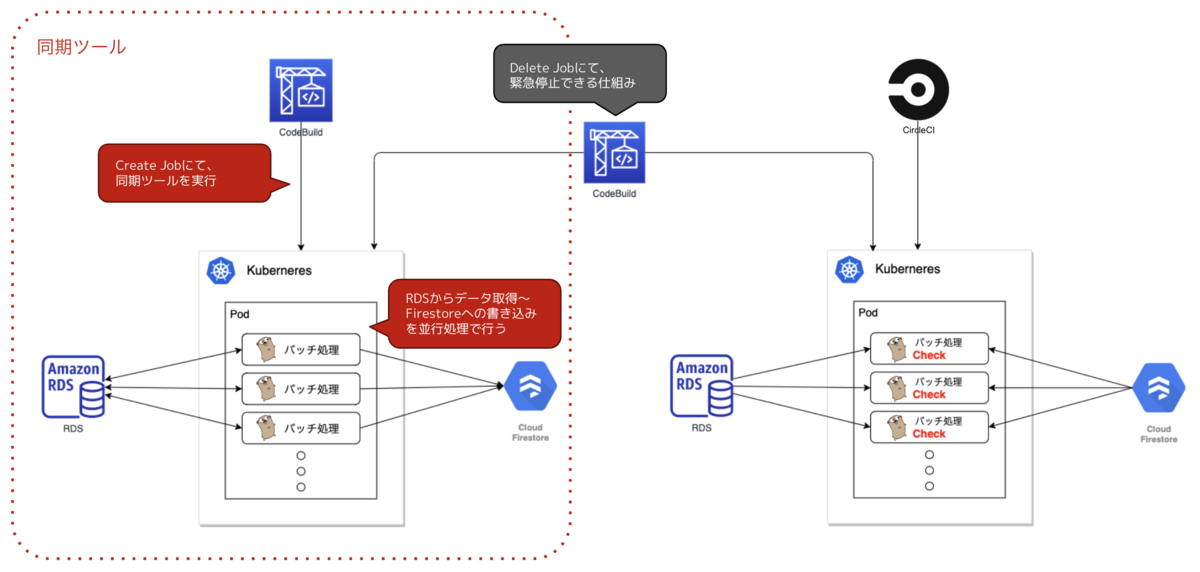
同期ツール
Go言語のバッチ処理をKubernetes Job上で実行するツールになります。RDSからデータを取得〜Firestoreに書き込みを並行処理で行っています。
Go言語のgoroutine(ゴルーチン)を使用して並行処理を行っています。
実行は、AWS CodeBuild上で手動で行えるようにしました。
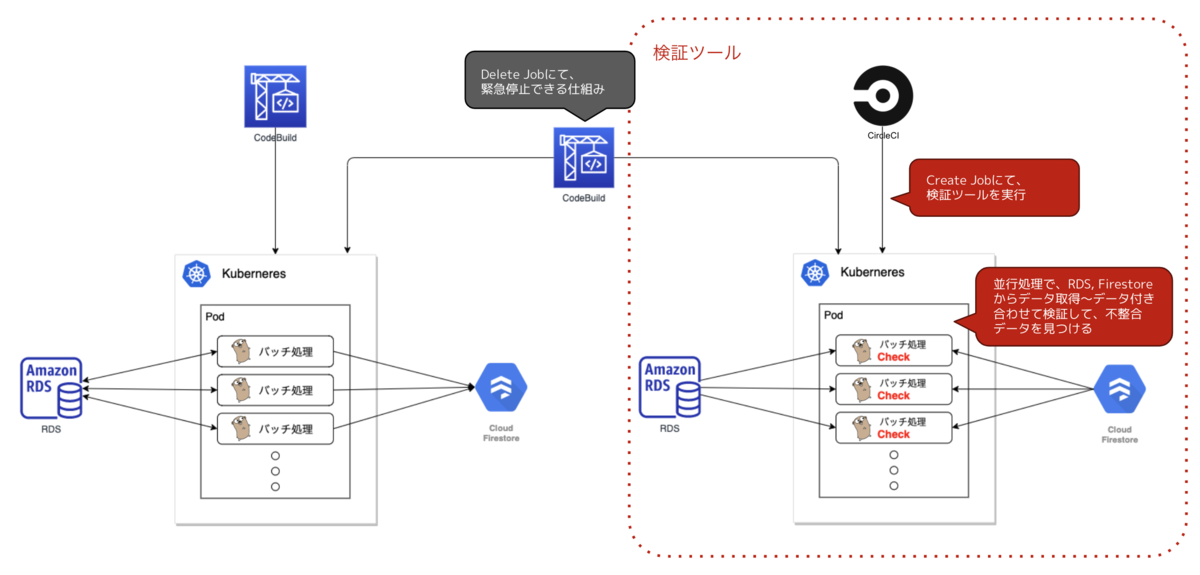
検証ツール
同期ツールと構成自体はほとんど同じです。 実行がCircleCIなのと処理の内容が違うくらいでしょうか。(実行がCircleCIなのは特に意味はなくCodeBuildでも問題なかったです)
処理の内容は、RDS、Firestoreからデータを取得〜1件ずつの付き合わせによるデータ検証を並行処理で行っています。
パフォーマンス向上の施策4選
トライ&エラーの繰り返しでとても大変な取り組みでしたが、その中でよかったこと4選という形でご紹介していきます。
1. 本番同等の検証環境を用意
まず、以下を検証用として別に用意しました。
- RDS
- Firestore
最初は、本番とデータ量もスペックも違う(少ない)RDSを使って、パフォーマンス検証を行っていました。 そして、いざ本番DBと同等のデータ量のRDSを用意して、同期ツールを実行してみたら実行時間が想定と大幅にかかってしまう結果になりました。
1万件のデータを1分で同期できたから、100万件だと100分で同期できるといった計算は通用しなかったのです。
ですので、パフォーマンス検証を行う際には、最初から実際に本番で実行する環境となるべく近いデータ量 スペックのDBを用意するのがとても重要に思いました。
2. 並行処理数とバッチサーバースペックの最適値を探る
こちらは、同期ツールの話です。 並行処理数を引き上げていくと、RDSか実行環境のバッチサーバーのCPUがボトルネックになることがほとんどでした。
RDSの調整は、いろいろ調整を検討する要素が多くあるかと思います。主に調整したのは、以下あたりでしょうか。
- クエリチューニング
- 1処理あたりのRDSからのデータ取得数
- コネクションを再利用する時間
- etc...
それに対して、バッチサーバーがボトルネックになっている場合に、スペックを上げるとその分だけパフォーマンスがよくなりました。
ですので、RDSとバッチサーバーのスペックのボトルネックを小さくしていきながら、並行処理数の最適値を探ると効率的なパフォーマンス改善に繋がるかなと思いました。
3. Firestoreへの書き込みをバッチ書き込みに変更
これは、移行先のFirestoreへの書き込みの話になります。 1件ずつ書き込んでいたものをFirestoreのバッチ書き込みを使用するように変更したところ、パフォーマンスにかなり効果がありました。
- Firestoreの公式ドキュメント firebase.google.cn
ちなみに、バッチ書き込みには、500件以上を一度に書き込めない制限があるので、アプリケーション側で調整する必要がありました。
その他にも制限がいくつかあるので注意して使って見てください。 firebase.google.cn
4. 本番DBのスナップショットの復元DBを使う
こちらは、パフォーマンス向上の施策ではないのですが、本番影響なしのデータ移行を実現できる良い手法でしたのでご紹介します。
上記のパフォーマンス施策を行い、結果的に全データ約5000万件を約5,6時間ほどで同期できるパフォーマンスを実現することができました。しかし、その時間本番DBへ負荷をかけ続けるのは、なかなか厳しかったので、結果的にこの方法を使いました。
結果的に、本番影響なしのため昼間の業務時間帯に安心してデータ移行を行うことができました。
データ検証で行ったこと2選
次に、データ同期後のデータ検証で行ったことを2つご紹介していきます。
1. 検証ツール上で不整合データをリカバリーできるようにした
同期ツール実行中にコネクションタイムアウトが発生することがわかっており、一部の同期漏れをスムーズにリカバリーするためにこの機能を追加しました。
同期ツールの同期不備だけではなく、運用による同期(SQS→Lambda→Firestore)の不備も検知・リカバリーできるため、新しいシステム構成へに載せ替えとしても必要な仕組みになっています。
現在は、この仕組みを平日深夜に定期実行させて、不整合データの検知とリカバリーを行っています。
2. データ不整合がなくなるまで、修正&実行の繰り返し
検証ツールによって検知された不整合データを一つ一つ、原因調査から修正を行い減らしていく作業です。 このデータ不整合の原因も以下のパターンあるので、減らしていくのにもなかなか大変でした。
- 同期ツールによるデータ同期
- 運用によるデータ同期(
SQS→Lambda→Firestore) - そもそも、検証ツールの判定方法が間違っている...
「運用によるデータ同期(SQS→Lambda→Firestore)」に関しては、データ移行後も付き合っていくことになるかと思います。
まとめ
本記事では、RDSからFirestoreへのデータ移行の進め方についてご紹介しました。 新しいデータベースへの載せ替えを検討されている方や、現在データ移行を行っている方にとって少しでお役に立てれば嬉しいです!
今回の内容ですが、先日こちらのイベントにて発表させていただきました。 tech.andpad.co.jp
以下がその時のLT資料になるので、よかったら読んでみてください〜! speakerdeck.com
次回テックブログを書く時は、きっとFirestoreが運用にのっている頃かなと思うので、「大量アクセスをSQS,Lambdaで捌く」みたいな内容の記事を書きたいなと思っています。
さいごに
アンドパッドでは一緒に働く仲間を募集しています。
新しい技術へのリニューアルや、マイクロサービス化などチームによって様々な取り組みを行っています。 少しでも興味をお持ちの方は、ぜひぜひご応募お願いいたします。 engineer.andpad.co.jp