はじめに
バックエンドエンジニアの須恵です。 過去の記事ではSREを名乗っていましたが、最近はGoでAPIサーバーを開発するのが主業務になっています。
依然SREチームの末席にも名を連ねさせていただいており、自分の開発しているAPIサーバーが乗っているKubernetesクラスターのメンテナンスや、クラスターに同居している他のサービスのCI/CD関連に取り組んだりしています。
会社のブログに寄稿するのは久しぶりです。
起きた問題
いつからか、そこそこ頻繁に、Podの更新が失敗する症状が発生するようになりました。
その際PodのステータスとしてErrImagePull または ImagePullBackOffが確認できました(ErrImagePullからImagePullBackOffに推移する)。
kubectl describeすると、このようになっています。

ErrImagePullの発生原因としてまず候補に挙がるのは「存在しないイメージをダウンロードしようとしている」というものですが、イメージはECRにpush済みであり、docker pullすることもできます。
Kubernetesが調整ループを根気よく回し続けた結果、数分後~数時間後には解消していることがほとんどだったのですが、解消までの時間にムラがありすぎるのと、CircleCIのジョブやHelmのrelease statusが失敗扱いになってしまい、開発体験に悪影響を与えていました。
(特にHelmについては、保存されるhistoryの上限を超えて失敗するとデプロイ可能な状態に復旧するのに手間がかかります)
先に結論から
原因
イメージのダウンロードは(実際には)進行中であるが、 kubeletのタイムアウト期間(デフォルトの1分)の間にDockerから進捗報告ができず、ダウンロードを打ち切られている。
対策
対症療法
今動いているノードのkubeletのオプション
--image-pull-progress-deadline=10m
を直接変更する。
根本対応
CloudFormationで作られたノードであるため
テンプレートでkubeletのBootstrapArgumentsに
--kubelet-extra-args "--image-pull-progress-deadline 10m"
を追加する。
ここからは、時系列で解決への道のりを書いていきます。
検索してIssueを発見
KubernetesのIssueを検索してみると、今回の困りごとと一致していそうなタイトルを見つけました。
このIssueのコメントに、
「kubeletに --image-pull-progress-deadline を設定しましたか?」
とあります。
(kubeletは、Kubernetesの多数あるコンポーネントのうち、ワーカーノードに常駐し、ノードのリソースやPodの状態を監視してAPIに送信したり、コンテナランタイムにコンテナ起動などの指示出しをするコンポーネントです)
続くこちらのコメント(および引用されたソースコード)によると、
「kubeletは、一定周期ごとにDockerからのイメージプル進捗報告を期待しており、進捗報告が得られない場合プルを打ち切る」こと、
「一定周期」は--image-pull-progress-deadlineで設定可能(デフォルトは1分)であることがわかります。
サポートに問い合わせ
本当にこのIssueと同件なのか、なかなか確信が持てず、確信に至るための打ち手も見えなかったので、AWSサポートを頼ることにしました。
(ところで、問い合わせの極意について、もうお読みになりましたか?)
サポートケースを開いて相談したところ、担当の方から、 「EKSログコレクターのログ提供」を手順を添えて依頼されました。
EKSログコレクターとは
こちらです↓↓
これは何
READMEを眺めてみると、
- OSのログ
- kubeletのログ
- Dockerデーモンのログ
を収集してアーカイブするシェルスクリプトのようです。
ログコレクターの実行まで
一刻も早くサポートへログを提供したいところですが、ここでまた壁にぶつかりました。
ノードに入る手段の確立
ログコレクターを実行するにはワーカーノードの中に入らなければなりませんが、問題のノードにはSSM エージェントはインストールしておらず、セキュリティグループでポート開放もしていませんでした。
一時的に開放して作業するか思案していたところで、このようなツールを発見しました。
これは、SSMエージェントがインストールされたコンテナをDaemonSetとしてデプロイし、かつノードのディレクトリをマウントすることで、後付けでセッションマネージャーを利用可能とするものです。
必要十分な取り扱い方がREADMEに記載されていますが、都合により一部異なる手順で利用します。
このクラスターではkube2iamを動かしているので、ノードに紐付いているロールを改変する必要はなく、DaemonSetにannotationを書き足すだけで十分です(同様に、公式のIAM Role for Service Accountsを利用しているクラスターであれば、そちらの仕組みに乗ることができます)。
template: metadata: annotations: # ポリシー AmazonEC2RoleforSSM を持つロール iam.amazonaws.com/role: arn:aws:iam::xxxxxxxxxxxx:role/ALLOW_SSM
また、eksctlで作ったクラスターではないので、下記のコメントアウトも必要でした。
# For debugging .env files produced by eksctl # - name: etc-eksctl # mountPath: /etc/eksct
# For debugging .env files produced by eksctl # - name: etc-eksctl # hostPath: # path: /etc/eksctl # type: Director
ログコレクターが動かない(パッケージ不足)
無事、kube-ssm-agentを利用してワーカーノードに入れるようになりました。 満を持してログコレクターを実行しますが、必要なパッケージが不足しておりエラーに阻まれます。
sh-4.2$ sudo bash eks-log-collector.sh
Fatal Error! Application "iptables" is missing, please install "iptables" as this script requires it, and will not function without it. Exiting!
それならばと、iptablesをインストールします。
sudo yum install iptables
備考
※本当にノードにパッケージが存在しないのではなく、コンテナ内部ではそのように認識されているだけだと思います(別件でkube-proxyの起動設定を見たときに--proxy-mode=iptablesだったため)。
今度こそ…
sh-4.2$ sudo bash eks-log-collector.sh
Fatal Error! Application "sysctl" is missing, please install "sysctl" as this script requires it, and will not function without it. Exiting!
なるほどそうですかと、procpsをインストールします。
sudo yum install procps
これでログコレクターが実行できるようになりました。
sh-4.2$ sudo bash eks-log-collector.sh
(略)
Done... your bundled logs are located in /opt/log-collector/eks_i-xxxxxxxxxxxxxxxxx_2020-03-18_0619-UTC_0.6.0.tar.gz
kube-ssm-agentの内部でログコレクターを動かしたため、生成物はkubectl cpを使ってローカルにダウンロードできます。
kubectl cp ssm-agent-24lnj:/opt/log-collector/eks_i-xxxxxxxxxxxxxxxxx_2020-03-18_0619-UTC_0.6.0.tar.gz ./eks_i-xxxxxxxxxxxxxxxxx_2020-03-18_0619-UTC_0.6.0.tar.gz
サポートからの回答
ようやくログをサポートに提出できました。 いただいた回答によると、やはりkubeletのタイムアウトが発生しているとのことでした。 根拠として、下記のログをピックアップして提示いただきました。
# 多少編集を加えています Cancel pulling image "略" because of no progress for 1m0s, latest progress: "d25013272171: Extracting [==================================================>] 88.27MB/88.27MB" level=error msg="Not continuing with pull after error: context canceled" PullImage "略" from image service failed: rpc error: code = Canceled desc = context canceled container start failed: ErrImagePull: rpc error: code = Canceled desc = context canceled Error syncing pod, skipping: failed to "StartContainer" for "略" with ErrImagePull: "rpc error: code = Canceled desc = context canceled"
「1分間進捗報告がなかった」ことにより、ErrImagePullへつながっています。
kubeletの設定変更を推奨されたので、実行します。
kubeletの設定変更
ユニットファイルを変更したあと、サービスを再起動します。 systemdのサービスとして動いていることを初めて知りました。
引き続きkube-ssm-agentが活躍します。
sudo vi /etc/systemd/system/kubelet.service
--image-pull-progress-deadline 10m \を追加します。
ExecStart=/usr/bin/kubelet --cloud-provider aws \
--config /etc/kubernetes/kubelet/kubelet-config.json \
--allow-privileged=true \
--kubeconfig /var/lib/kubelet/kubeconfig \
--container-runtime docker \
--image-pull-progress-deadline 10m \
--network-plugin cni $KUBELET_ARGS $KUBELET_EXTRA_ARGS
サービスを再起動します。
sudo systemctl daemon-reload sudo systemctl restart kubelet
今回問題が起きていたのは開発環境のクラスターであったので、実際はそれほど気を揉むことなくエイヤと行いましたが、ノードとPodが定常状態(=リソース状況、Podの状態に急激な変化なし、かつコンテナランタイムに指示出し中ではない)であれば、 特に我々が運用しているサービスの側にダウンタイムが発生する懸念はありません。
処置後の経過観察
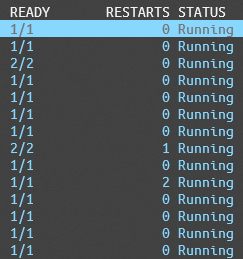
デプロイを何度も試行してみないことには効果が現れているか確認ができないので、気長に様子を見続けます。
すると、明らかに症状が改善していることがわかりました。
kube-ssm-agentの除去
便利な反面、稼働させたまま放置しておくのはセキュリティ的によろしくありません。 用が済んだら削除しておきましょう。
kubectl delete ds ssm-agent
こうして簡単に削除できるのも利点ですね。
おわりに
自分の運用しているクラスターで開発体験が悪化することは慙愧の念に堪えませんが(というか、自分も開発しているから困る)、今まで知らなかったことを学ぶ良い機会になりました。
もっとKubernetesに詳しくなっていきたいです。